Almost anything you do in programming can be used as a learning experience. It's a fine line between doing everything from scratch and re-inventing the wheel, and standing on the shoulders of others so you can reach further. There is so much out there in the way of frameworks, scaffolding, tools to help you achieve what you want to achieve. While it's great to be able to use these fantastic tools, it is also extremely beneficial to have some understanding of what's going on under the surface.
I've been hand-coding in Perl for pretty much my whole career, without using an existing framework. As such, I've been developing my side-projects after hours using modern programming languages and frameworks to try and broaden my skill set and stay relevant in the world of web development. For the past few months I've been developing using the Flask framework for Python. The very blog site you're reading now is written by myself using Flask. Yes, I could have just used an "off the shelf" solution for blogging, such as Wordpress, but in doing so I wouldn't really learn anything.
Along the way I've run in to small problems, mostly caused by not being totally familiar with what I'm doing in Python and Flask, but these too have presented interesting learning challenges. As an example, the blog entries on this site are created and formatted using the Markdown syntax. I'm also running the content through Python's Bleach library for sanitising the markup. So far, so good.
I then wanted to truncate the blog entries for display on the home page of the blog. This isn't as simple as just taking a slice of the string representing the content, because we might end up with broken and un-nested HTML tags. I was lucky enough to stumble across this interesting snippet which appeared to hold all the answers I was looking for. The code uses a Python class derived from the HTMLParser library to build up a tag stack, truncate the HTML content and ensure the tag stack is closed correctly.
I implemented the code on my site, pushed it to production, and all was well.
The next day I decided to alter my code to allow <img /> tags for displaying images within my blog posts. I edited a blog post on my test environment, reloaded the home page - and everything broke.
Exception: end tag u'p' does not match stack: [u'p', u'img']
What? I thought the HTMLAbbrev code was supposed to take care of this for me?
Digging deeper in to this, I found that the HTMLAbbrev class was overriding the methods for handle_starttag, handle_endtag and handle_startendtag, inherited from the base class of HTMLParser. handle_startendtag is similar to handle_starttag but it applies to empty tags such as <img />. Ok, this is somewhere to start looking.
The HTML output of my blog post was coming up with
<img class="float-left" height="200" src="http://s3-ap-southeast-2.amazonaws.com/matthealy-blog/1024px-Cable_closet_bh.jpg">
which isn't correct XHTML style. Perhaps this is why the HTMLParser module couldn't process my HTML?
Backtracking through the code to find out where the responsibility lies, I isolated the problem to Bleach itself. "Surely this has come up with others before me?" I thought. I checked the project's GitHub Issues page, and found the following closed issue
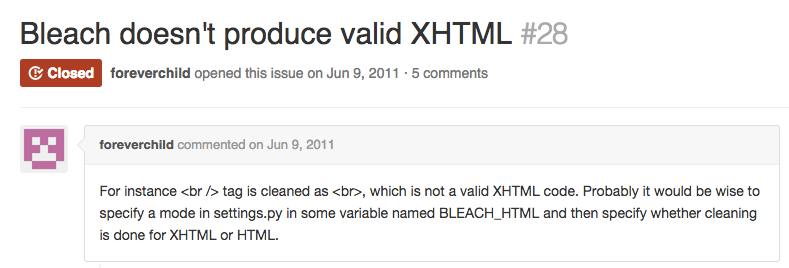
This looks promising, but the issue was closed due to lack of interest! (This is the good and bad thing about open source software - if something is broken, feel free to fix it yourself!) A commenter in that thread mentioned that they were using Beautiful Soup to tidy up the HTML and make sure it is formatted as XHTML. I installed the package to my site, ran my HTML content through Beautiful Soup and called soup.prettify() and hey presto, we have valid XHTML, and the HTMLAbbrev class can once again handle my blog posts.
I finally thought that all was working as expected, but no, there was one more hurdle to overcome! It turns out that using soup.prettify() adds a whole bunch of extra whitespace around your HTML elements, making your anchor links look funny. I found this article providing the answer - use str(soup) instead of soup.prettify().
Finally I end up with the desired result, with the added satisfaction of nutting out a few little problems along the way.